This article is from: Tencent Big Data
Introduction
In order to support the computational model calculation of the extremely large dimensional machine, the Tencent Data Platform Department and the Hong Kong University of Science and Technology have developed a distributed computing framework for machine learning, Angel 1.0.
Angel is a proprietary machine learning computing system developed using the Java language. Users can use it to do machine model training like Spark or MapReduce. Angel has supported SGD and ADMM optimization algorithms . At the same time, we also provide some commonly used machine learning models; however, if the user has custom requirements, the model can be easily encapsulated in the upper layer provided by our optimization algorithm.
Angel used Chukonu of the Hong Kong University of Science and Technology as a network solution to speed up the parameter passing of lagging computing tasks in the process of updating parameters of high-dimensional machine learning, and overall shortened the operation time of machine learning algorithms . This innovation uses the network-optimized application-aware network optimization solution developed by Professor Chen Kai and its research team at the Hong Kong University of Science and Technology, and the large-scale machine learning research program led by Professor Yang Qiang.
In addition, Professor Cui Bin from Peking University and his students also participated in the research and development of the Angel project.
In actual production tasks, Angel runs SGD at a characteristic latitude of tens to hundreds of millions of levels, and the performance is several times to several dozen times that of the mature open source system Spark. Angel has been practically applied in Tencent's video recommendation, WidePoint, and other precision recommendation services. At present, we are expanding the scope of application within Tencent. The goal is to support Tencent and other enterprise-level large-scale machine learning tasks.
Overall structure
Angel refers to Google's DistBelief on the overall architecture. DistBeilef was originally designed for deep learning. It uses a parameter server to solve the huge model updates during training. Parametric servers can also be used for non-deep learning models in machine learning. For example, SGD, ADMM, and LBFGS optimization algorithms require distributed caching of parameters to extend performance in a scenario where billions of parameters are updated at each iteration. Angel supports three computing models: BSP, SSP and ASP. The SSP is a computational model validated by Eric Xing of Carnegie Mellon University in the Petuum project. It can improve the shortening of the convergence time in this particular operating scenario of machine learning. The system has five roles:
Master : Responsible for resource application and distribution, as well as task management.
Task : responsible for the execution of the task, in the form of threads.
Worker : The independent process runs in Yarn's Container and is the Task's execution container.
ParameterServer : Generated with the start of a task. The task ends and is destroyed. It is responsible for updating and storing parameters in the task training process.

The WorkerGroup is a virtual concept consisting of several Workers whose metadata is maintained by the Master. Considering the parallel development of the model, the training data of all workers in a WorkerGroup is the same. Although we provide some common models, there is no guarantee that they will satisfy the requirements, and user-defined model implementations can implement our common interface, which is equivalent in form to MapReduce or Spark.
1) User-friendly
1. Automated data segmentation : The Angel system provides users with the ability to automatically segment training data to facilitate the user to perform data parallel operations: the system is compatible with the Hadoop FS interface by default, and the original training samples are stored in a distributed file system supporting the Hadoop FS interface. Such as HDFS, Tachyon.
2. Abundant data management : sample data is stored in a distributed file system. The system reads from the file system to the computing process before calculation, and caches it in memory to speed up iterative operations; if the data is not cached in memory, then Save to local disk, no need to re-initiate communication requests to the distributed file system.
3. Abundant linear algebra and optimization algorithm library : Angel also provides efficient vector and matrix operation library (sparse/dense), which is convenient for users to freely select the expression form of data and parameters. In terms of optimization algorithms, Angel has implemented SGD and ADMM; in terms of models, it supports Latent Dirichlet Allocation (LDA), MatrixFactorization (MF), LogisticRegression (LR), and Support Vector Machine (SVM).
4. Optional calculation model : We mentioned in the review that Angel's parameter server supports BSP, SSP, and ASP calculation models.
5. More fine-grained fault tolerance : In the system, fault tolerance is mainly divided into Master fault tolerance, parameter server disaster recovery, cache of parameter snapshots in the worker process, and fault tolerance of RPC calls.
6. Friendly task operation and monitoring : Angel also has a friendly way of running tasks and supports Yarn-based task operation mode. At the same time, Angel's Web App page also makes it easier for users to view the progress of the cluster.
2) parameter server
In the actual production environment, Spark's Driver single-point update parameters and broadcast bottlenecks can be intuitively perceived. Although it is possible to reduce the time-consuming calculation by linearly expanding, it brings with it a problem of reduced convergence and serious problems. In the data parallel operation process, since each Executor keeps a complete parameter snapshot, the linear expansion brings the flow of N x parameter snapshots, and this traffic is concentrated on one node of the Driver!

From the figure, we can see that in machine learning tasks, Spark cannot be used even if there are more machine resources. The machine can only perform at its best performance on a relatively small scale, but this optimal performance is actually not ideal.
Using the parameter server approach, we compared the following with Spark: In a data set with 50 million training samples, a logistic regression model using SGD solution was used, and 10 work nodes were used to perform the characteristics of different dimensions one by one. Comparison of each iteration time and overall convergence time (here Angel uses BSP mode).
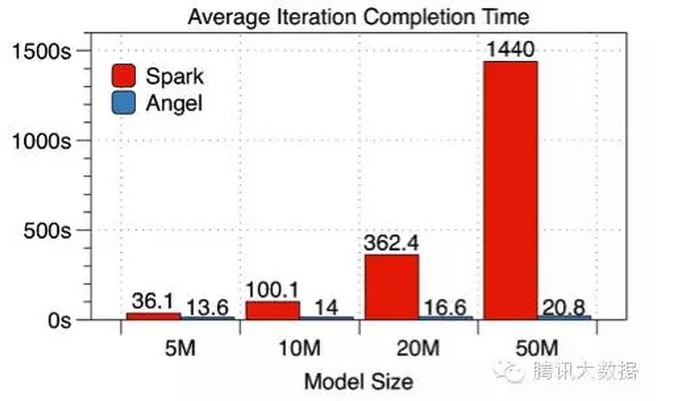
As can be seen from the data, the larger the model, the more obvious the advantage of Angel vs. Spark.
3) memory optimization
An asynchronous lock-free Hogwild! mode was used during calculations to reduce memory consumption and improve single-process convergence. If the N Tasks in the same computing process each maintain an independent parameter snapshot in the operation, the memory overhead for the parameters is N times. The greater the model dimension, the more obvious the consumption! In the optimization algorithm of SGD, in the actual scene, the training data is sparse in most cases, so the probability of the conflict of parameter update is greatly reduced. Even if the conflict is not the gradient, it is not entirely the direction of development. After all, it is the DPRK. The direction of the gradient is updated. We used the Hogwild! mode to allow multiple Tasks to share the same parameter snapshot in one process, reducing memory consumption and increasing the speed of convergence.
4) Network Optimization
We have two main optimization points:
1) The parameter update after the in-process Task operation is smoothly pushed to the parameter server update after the consolidation, which reduces the upstream consumption of the Task's machine, and also reduces the down consumption of the parameter server, while reducing the peak value during the push update process. Number of bottlenecks;
2) Deeper network optimization for SSP: Since SSP is a semi-synchronous operation coordination mechanism, running training in a limited window, when the fast nodes reach the edge of the window, the task must stop and wait for the slowest node update. The parameters. In response to this problem, we have accelerated the slower working nodes through the redistribution of network traffic. We give higher bandwidth to the slower nodes; correspondingly, the fast working nodes share less bandwidth. In this way, the difference between the number of iterations of the fast node and the slow node is controlled, reducing the probability of the window being broken (waiting to occur), that is, reducing the idle waiting time of the working node due to the SSP window.
As shown in the figure below, in the 100 million-dimension, iterative 30-round performance evaluation, we can see that Chukonu has significantly reduced the accumulated idle waiting time by 3.79 times.
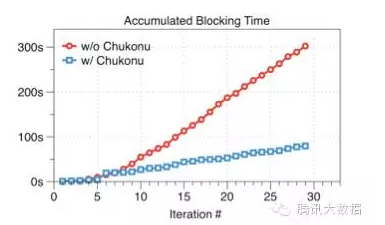
The following figure shows the execution time before and after optimization. Take a 50-million-dimension model as an example. 20 work nodes and 10 parameter servers, Staleness=5, execute 30 iterations. It can be seen that the average completion time for each round of Chukonu is only 7.97 seconds, which is a 15% improvement compared to the original task of 9.2 seconds per round.

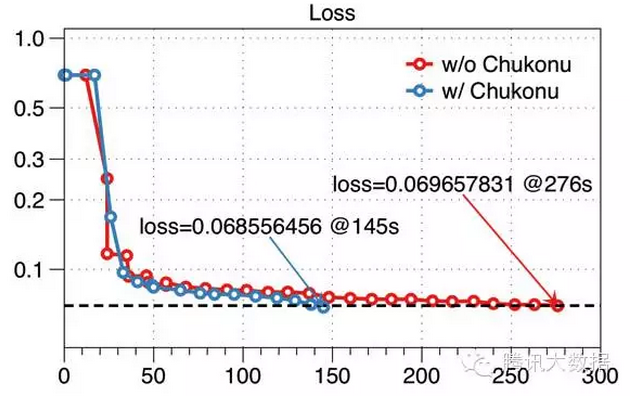
In addition, nodes that are slow in targeted acceleration can make the slower nodes more likely to obtain the latest parameters. Therefore, compared with the original SSP calculation model, the convergence of the algorithm is improved. As shown in the figure below, the performance evaluation of the 50 million-dimension model under the SSP is also performed. The original Angel mission after the 30 iterations (276 seconds) loss reaches 0.0697, and after the Chukonu is started, it is iterated at the 19th round. (145 seconds) has reached a lower loss. From this particular scenario, there is a nearly 90% increase in convergence speed.
Follow-up plan
In the future, the project team will expand the scale of the application. At the same time, the project team has continued to develop the next version of Angel. The next version will do some in-depth optimization of the model in parallel. In addition, the project team is planning to open the Angels open source, we will make public at the appropriate time.
This article is reproduced exclusively by Tencent Big Data. Please contact the original author if you need to reprint it.
Switching Mode Power Supply,Gold Plating Power Supply,Intelligent Pulse Power Supply ,Switching Power
Shaoxing Chengtian Electronic Co., Ltd. , https://www.ctnelectronicpower.com