According to the characteristics of video surveillance, this paper mainly discusses the software implementation process and key technologies involved in MPEG-4 in video surveillance applications, focusing on the parts that were not in the previous standards, including VOP generation, shape, texture, and motion. Encoding, with special emphasis on Sprite encoding and scalable encoding.
This article refers to the address: http://
Keywords MPEG-4 VOP generation Sprite coding scalable coding
The Software Realization of MPEG-4 Based on video surveillance application
Li Qing-ping , Shi Zhong-suo, Chen Ming (University of Science and Technology Beijing, Information Engineering Institute, Beijing, 100083) Abstract Due to the characters of video surveillance, this paper mainly discusses the softwarerealization of MPEG-4 based on video Surveillance application. Also the related key techniques including the generation of VOP, shape coding, texture coding, motion coding are presented and the novel techniques that do not appear in the previous standard are emphasized, for example,Sprite coding and scalable coding.
Key words MPEG-4, VOP generation, Sprite coding, Scalable coding
1 Introduction <br> At present, the image compression standards for digital video surveillance are mainly H.261 and MPEG-1, and they have certain limitations in practical applications. First, their adaptability is poor, and the transmission rate cannot be adaptively adjusted according to the network conditions, so that the performance of the network is drastically reduced when congestion occurs. Second, they do not have strong user interaction. MPEG-4 can make up for the above shortcomings, and it has the unique advantage of monitoring applications: since the compression ratio is more than ten times that of MPEG-1 of the same quality, it can greatly save storage space and network bandwidth; error recovery capability is strong: when the network When there is a bit error or packet loss in transmission, MPEG4 is less affected and can be recovered quickly; the image quality is high: it can achieve the effect close to DVD.
2 Design ideas <br> According to the image characteristics of video surveillance and its real-time requirements, the coding software is designed in consideration of the instability of the actual network. The original image of video surveillance has a notable feature that there are a large number of background objects that are stationary or rarely moving. The most basic idea of ​​MPEG-4 is object-based coding. The basic unit of codec is the object. So you can split the image into moving object objects and background objects. The background object is encoded by a method with high compression and large loss, and the moving object object is coded by a method with low compression and small loss. Based on this, we use the idea of ​​Sprite encoding in MPEG-4 to encode the background object. This is a key point of software implementation. In view of the real-time requirements of video surveillance, in addition to increasing the compression ratio, the complexity and complexity of the algorithm should be considered in order to meet the real-time requirements. This idea runs through the entire process of coding, such as the definition and generation of VOPs, Sprite coding, and so on. In addition, considering the instability of the network, the MPEG-4 scalable coding concept is adopted.
3 MPEG-4 software implementation process <br> Now, MPEG-4 based applications are mostly hardware solutions, using a special MPEG-4 encoding chip, it is difficult to upgrade, and the flexibility is also poor, and the software solution is used in this paper. It can be coded according to the actual application requirements, easy to upgrade in the future, and has great flexibility. In this paper, natural video coding is implemented, and audio coding is not involved. The overall steps in software design are to first generate VOPs using image segmentation techniques, followed by Sprite generation, and finally the encoding of each VOP. The software implementation process is shown in Figure 1. The key technologies are introduced below, focusing on what is not in the previous standards: definition and generation of video object plane VOP (video object plane), sprite generation and coding, shape, motion, texture coding, and scalable coding. In MPEG-4, there are four types of VOPs, I-VOP, P-VOP, B-VOP, and S-VOP. For normal video objects, only the first three are involved, and S-VOP refers to SpriteVOP.
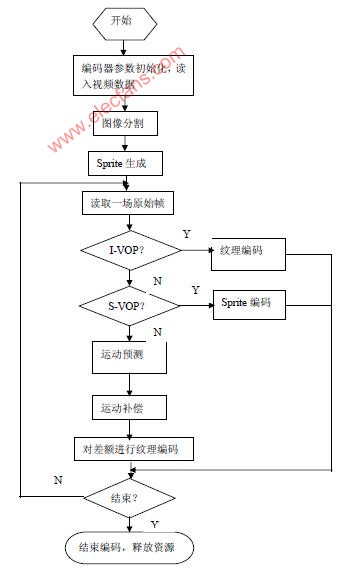
3.1 Definition and generation of VOP
The coding unit of MPEG-4 is VOP, but the standard does not specify the specific algorithm for generating VOP, but it is included in the public research content. The generation of VOP is achieved by video segmentation. Video segmentation is the basis for implementing object-based video coding systems and a difficulty for MPEG-4 coding. Image segmentation technology is divided into three types: texture-based segmentation, motion-based segmentation, and space-time segmentation based on the information used for segmentation. According to the degree of human participation, image segmentation is divided into automatic segmentation and semi-automatic segmentation. Automatic segmentation does not require user participation. It only needs to set some basic parameters, and the video object can be automatically segmented by the segmentation algorithm, but the result is not very accurate, mainly used for real-time coding; semi-automatic segmentation requires user participation, so it can be obtained. Accurate semantic objects and boundaries, primarily for content-based manipulation and interactive access. The requirement for image segmentation based on encoding is not very high, mainly in real-time. Here, a space-time joint automatic video object segmentation algorithm is selected. The algorithm firstly uses the F-hypothesis test based method to obtain the initial change detection template for time domain segmentation, and then obtains the final motion object by merging with morphological-based spatial domain segmentation. This algorithm is relatively simple to calculate and can better separate the foreground moving objects from the background. The algorithm is detailed.
3.2 Sprite coding
Sprite encoding is a new generation of encoding technology that uses global motion estimation to generate a sprite image (panoramic) of the video segment background, and then encodes the sprite image. The background encoding of each frame is only the motion of the frame relative to the sprite image. The parameters are encoded. Based on the characteristics of background smoothing and texture correlation, the encoding of Sprite panorama adopts a direct spatial prediction method. Based on the space limit, it is not introduced here. Refer to [2]. Sprite encoding consists of two parts, one is the generation of Sprite, generated using global motion estimation; the second is Sprite encoding. Sprite was built before the original VOP encoding, and two types of Sprites were defined in the MPEG-4 standard: static sprites and dynamic sprites. Dynamic Sprites are chosen here, so we will only discuss the generation and encoding of dynamic Sprites.
The encoding of the dynamic sprite is shown in Figure 2: the first frame of the video sequence is encoded by the I-VOP method, and the reconstructed image of the first frame establishes the same initial Sprite image at the encoding end and the decoding end; The estimation algorithm estimates the global motion between the current VOP and the previous frame VOP, and describes the motion between the two VOPs using the trajectory of the reference point. The P-VOP method is used to encode the texture of the second frame. The difference is that when encoding each macroblock of the VOP, the motion compensation method can compensate the motion of the macroblock and the block motion, and the motion can be compensated by using the Sprite image as a reference. The motion compensation of the block is global motion compensation. The trajectory of the decoding reference point of the decoder obtains a global motion parameter, then the texture information is decoded to obtain a reconstructed image of the second frame, and the Sprite image is updated according to the global motion parameter and the second frame reconstructed image. The same method is used to encode the VOP behind the sequence.
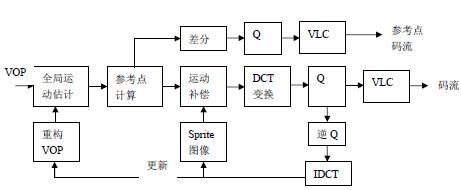
Figure 2 Dynamic Sprite Encoding Block Diagram
3.3 Scalable coding According to the characteristics of video surveillance, when the resolution and frame rate of the transmitted image are not very high, the monitoring effect under the general requirements can still be achieved. So we can use MPEG-4's object-based layered transport idea, use the spatial grading function to adjust the spatial resolution, and use the time domain grading function to adjust the frame rate. On the one hand, it is convenient to implement rate control, and it has good adaptability to changes in network bandwidth. On the other hand, users can select resolution and frame rate through interactive functions to obtain better video effects or obtain The local details of an object. MPEG-4 defines a common scalable extension framework for spatial and temporal scalable expansion, as shown in Figure 3.
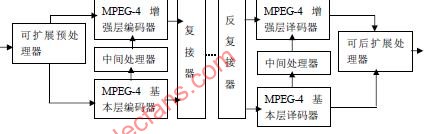
Figure 3 MPEG-4 universal scalable extension framework
When used for spatial domain extension, the scalable preprocessor downsamples the input VOP to obtain the base layer VOP processed by the VOP encoder. The intermediate processor processes the reconstructed base layer VOP and upsamples it, and the difference between the original VOP and the intermediate processor output is used as an input to the enhancement layer encoder. The encoding in the enhancement layer is encoded in P-VOP or B-VOP mode. The base layer and the enhancement layer code stream corresponding to the base layer and the enhancement layer decoder can be separately accessed through the repeated connector, and the intermediate processor on the decoder side performs the same operation as the encoding end, and the extended post processor performs necessary conversion work.
When the spreading code uses time domain extension coding, the scalable preprocessor decomposes one VO into two substreams of the VOP in the time domain, one of which is input to the base layer encoder and the other to the enhancement layer encoder. . In this case, no intermediate processor, but simply present the decoded base layer VOP VOP is input to the enhancement layer encoder, the enhancement layer encoder uses temporal prediction them. The scalable post processor simply outputs the VOP of the base layer without any conversion, but mixes the base layer and the enhancement layer VOP in the time domain to produce an enhanced output with higher temporal resolution.
3.4 Shape, Motion, and Texture of Ordinary VOPs Coded shape coding is not available in other coding standards. There are two types of coded information: binary shape information and gray scale shape information. Binary shape information is the shape of the encoded VOP by 0, 1 method, 0 means non-VOP area, 1 means VOP area; gray level shape information can take values ​​0~255, similar to α plane in graphics The concept, 0 means non-VOP area (ie transparent area), 1~255 means the difference of transparency of VOP area, 255 means completely opaque. The introduction of gray-scale shape information is mainly to make the foreground object superimposed on the background without being too obvious and too blunt, and to perform the blurring process. Here, the binary shape uses a context-based arithmetic coding method [4]. The whole coding process can be divided into the following five steps: 1 Re-determining the shape boundary for a binary shape map of a given VOP, and dividing it into several 16×16 Binary Alpha Block (abbreviated as BAB). 2 Perform motion estimation on the BAB block to be encoded to obtain motion vector MVs (MV for shape is abbreviated as MVs). 3 Determine the coding mode of the BAB block to be encoded in the VOP. 4 Determine the resolution of the BAB block to be encoded. 5 encode the BAB block. Gray scale encoded shape coding is similar. For normal video objects, the MPEG-4 encoding algorithm supports three types of VOPs: I-VOP, P-VOP, and B-VOP. Motion prediction and motion compensation in MPEG-4 can be based on 16x16 macroblocks or 8x8 blocks. If the macroblock is completely within the VOP, motion estimation is done using a general method; if the macroblock is at the VOP boundary, image fill techniques are used to assign values ​​to pixels outside the VOP. These values ​​are then used to calculate the SAD. For P-VOP and B-VOP, the motion vector is first differentially encoded, and then the variable length is used to encode the motion vector.
The texture information of the video object is represented by the luminance Y and the two color difference components Cb, Cr. For the I-VOP, the texture information is directly included in the luminance and the color difference component, and in the case of motion compensation, the texture information is compensated by the motion compensation. The difference is indicated. The encoding of texture information uses a standard 8*8 DCT. In texture coding, both intra-frame VOP and motion-compensated residual data are coded using the same 8x8 block DCT scheme, and DCT is performed on luminance and chrominance, respectively. For macroblocks within a VOP, the same technique as H.263 is used. For macroblocks located at the edge of a VOP shape, there are two options. One is to fill the portion of the macroblock other than the VOP with image filling technology, and the other is It is a method of shape adaptive DCT coding. The latter only encodes the pixels inside the VOP, so that it has higher quality at the same bit rate. The cost is that the complexity of the application is slightly higher. Considering the real-time requirements of video surveillance, the low-pass in the image filling technology is selected. Extrapolation method (Low PassExtrapolotion). Then do DCT. Data quantization, scanning and variable length coding operations after DCT are similar to MPEG-2 and H.263 and are not detailed here.
4 Summary <br> According to the characteristics of image monitoring system, this paper draws on the idea of ​​MPEG-4 coding standard, and proposes the main framework of software to realize MPEG-4 coding in video surveillance applications. Compared with the current hardware solutions. It is closer to the requirements of practical applications, with great flexibility and upgradeability, and can reduce costs. However, due to the complexity of MPEG-4 encoding and its technical imperfections, there are certain difficulties in implementation, especially how to maintain its real-time performance. With the emergence of high-speed processing chips and the technical advancement of MPEG-4, these problems will be solved.
CSRM safety relay fulfills the safety requirements of ISO13849- 1Cat.4, applies to monitoring of signals of industry field with high safety requirements, including emergency stop signal, safety gate switch signal, Safety Light Curtain signal, safety light curtain signal with pulse output and two-hands button signal.
Safety Relay Module,Emergency Stop Module,Relay Module,Electric Safety Smart Module,Electric Safety Relay,Smart Relay Module
Jining KeLi Photoelectronic Industrial Co.,Ltd , http://www.sdkelien.com